

There should be no doubts in anyone’s mind about how Big Data and AI are fueling the next revolution. Data is the new oil, and AI refines the oil. The questions to ask is the following:
- How well are you placed to use data as a strategic asset?
- Are your technologies equipped to harness data effectively? At the right speed and in the proper manner?
- Are you able to reduce the data to insight turnover time and ensure that the right insight is available to the right stakeholders promptly?
Data Engineering has become vital for any organization that is serious about harnessing data.
This blog illustrates how Azure Databricks strives to modernize and yet simplify data engineering to reduce the data to insight turnover time.
Let us start by understanding the market.

According to IDC, there are three major trends when it comes to Data and AI.
- The 1st is the astronomical explosion of data: By 2025, data will reach around 175 ZB. To put things into perspective, 1 PB is equivalent to 13.3 years of HD video. 1 ZB is equal to 13.3 million years of watching HD video. That is a binge-watching till infinity.
- The 2nd trend is AI investment. 80% of organizations are experimenting with AI-related technologies. No one wants to be left behind. The mantra is: adapt or die.
- The 3rd major trend validates the 2nd trend. AI investment is skyrocketing and is poised to increase by 300% through 2023.
Cloud computing is the primary catalyst to make these changes happen. Cloud enables innovation.

Forbes predicts that, in 2030, the global business value derived from Advanced Analytics & AI will be $15 trillion. This bucket is distributed across smart products, virtual agents, and decision automation.
The potential is immense.
The Challenges
The path to innovation is never easy. It has its roadblocks. Three key challenges that prevent organizations from realizing their objectives with Big Data projects are:
- The complexity of solutions: There are so many data engineering solutions and offerings that is becomes difficult to understand and implement them.
- Data silos: Siloed data across teams and departments inhibit the development of unified data pipelines.
- Scaling: Scaling challenges and model performance constraints often represent a cost and implementation barrier for data engineering teams.
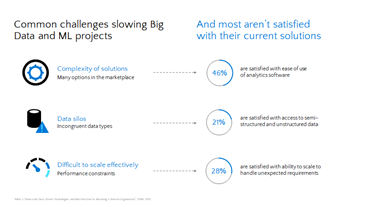
By mapping these challenges to the study conducted by TDWI, it is clear that most companies are not satisfied with their current solutions:
- Less than half are satisfied with the ease of use of their analytics software.
- Only 21% are satisfied with their access to semi-structured and unstructured data.
- And only 28% are satisfied with their ability to scale to handle unexpected requirements.
New problems strive for new solutions. Addressing these considerations requires a modern data engineering strategy.
Azure Databricks
Azure Databricks strives to hit the sweet spot. Azure Databricks is the jointly-developed Data and AI service from Databricks and Microsoft with a razor-sharp focus on data engineering and data science.
Let us deep-dive into the key five capabilities of Azure Databricks.

Azure Databricks provides five key capabilities:
- It is a powerful data processing engine. Azure Databricks, as I like to call it, is Spark on steroids. The enhancements made to the Databricks Runtime has made it up to 10x faster than open-source Apache Spark™. It leverages Azure Data Lake Storage to process both streaming and batch data at scale with almost zero maintenance.
- It is a first-class Azure product. What is means is that it has parity with any other Azure service and has tight integration to many Azure services, including Azure Machine Learning, Synapse, Azure Data Factory, and Azure DataLake Storage (ADLS). Nowhere in the cloud world exists such tight integration with Databricks.
- It provides a platform for end-end lifecycle management of data engineering and data science workloads using collaborative workspaces and notebooks. That means that multiple teams can work on the same data engineering job without overwriting each other.
- It provides best-in-class security features. It provides enterprise-grade security with encryption, fine-grained role-based access control, and is HITRUST certified, building on the foundation of HIPAA, NIST, ISO, COBIT, and SOC 2.
- Last but not least, it is a platform as a service. That implies there is minimal maintenance overhead. Compute and Storage are decoupled. Customers get excellent value for money.
Azure Databricks along with Azure’s ecosystem offers a solution that is innovative, scalable, and focuses on value at the right cost.
Modern Data Engineering on Azure
Now that there is a better understanding of Azure Databricks, let us deep-dive into the Architectural constructs of a modern data engineering platform.

These are the four critical pillars of modern data engineering. Ingest. Store. Prep and Train. Model and Serve. It will look traditional, but the devils are in the details.
Let us drill down into it:
- The Ingestion: The data is ingested and stored in the data lake store. Azure Data Factory, Azure’s defacto data integration tool, provides more than 50 connectors that will enable us to integrate data from disparate sources into the raw data lake.
- The Storage: Azure Data Lake Store provides HDFS compliant storage, which theoretically has limitless capacity. ADLS can natively store data in Delta Format that provides additional capabilities like ACID compliance, schema enforcement, data versioning, audit history, to name a few.
- The Preparation: Now we are into the kitchen, Azure Databricks has all the right ingredients to process both batch and streaming data, at scale and make it ready to be served to stakeholders. As you would know by now, it will use best in class Apache Spark for the processing. It will also streamline the workflow, and one can also deploy ML workflows using Azure Databricks.
- The Serving: Here comes the power of Azure Synapse that has native integration with Azure Databricks. Synapse is an on-demand Massively Parallel Processing (MPP) engine that will help to serve the data for reporting and downstream analysis include Azure Machine Learning.
The Architecture is scalable, on-demand, with built-in high availability (HA), and is capable of processing and serving petabytes of data at lightning speed.
Key Takeaways
The architecture illustrated in the previous section is tried and tested with multiple customers across the globe. Architecture is such that it gives the right levers for cost and functionality control.
There are a few fundamental principles to note in this Architecture:
- All components are platform-as-a-service: This implies that it has built-in HA and can be configured to only pay for what you use.
- Compute is decoupled from Storage: Now, that is very neat. The Storage is persistent, and the compute ephemeral. You spin up on-demand, process what you need, and then shut it down. Pay for only the time it processes.
- All components are loosely coupled but tightly integrated. The components used in Architecture integrate very well with each other. The development effort to weave them together is minimal. They are also loosely coupled. One can replace any component with another component that satisfies the same functionality without impacting others.
This Architectural pattern enables data engineers to focus on doing data engineering with a single goal in mind: To reduce data to insight turnover time. Focus less on technicalities. Focus more on functionality.